Call a Specialist Today! 844-356-5139 Free Shipping! On Any Order over $150
QNAP QAI-h1290FX A GPU-ready edge AI storage server supporting NVIDIA® GPUs, U.2 NVMe SSDs, and 25GbE connectivity—designed for on-premises AI, virtualization, and compute-intensive workloads.
QNAP Products
Enterprise Storage Products
QNAP 12-Bay U.2 NVMe PCIe Gen4 x4 all-flash desktop NAS, AMD EPYC 16-core 7302P, 12 x 2.5″ U.2 NVMe / SATA SSD bays, 128GB RDIMM ECC DDR4 RAM, 2 x 2.5GbE RJ45, 2 x 25GbE SFP28, PCIe Gen4 expansion slots, 750W single power supply with dual PCIe 8pin, up to 300W GPU AMD EPYC™ 7302P, 16C/32T up to 3.3 GHz
QAI-h1290FX is a desktop-class edge compute and storage convergence server that combines high-performance computing architecture with ultra-fast storage. It supports configurable NVIDIA® RTX™ PRO Blackwell GPUs, making it ideal for on-premises AI, LLM inference, private RAG search, virtualization, and other demanding compute workloads.
Powered by QuTS hero with the ZFS file system, the platform delivers enterprise-grade data integrity and consistent performance. Whether for AI deployment, research and development, high-performance computing, or enterprise virtualization environments, QAI-h1290FX enables flexible configuration and rapid deployment, ensuring critical workloads run securely and efficiently at the edge.
GPU-Ready Architecture with RTX PRO Blackwell Support
Built with a GPU-ready design, supporting NVIDIA® RTX™ PRO Blackwell GPUs, including options such as the RTX PRO 6000 Blackwell Max-Q Workstation, to meet the demands of AI workloads, image generation, inference, and GPU-accelerated computing.
High-Speed All-Flash NVMe Storage Architecture
Equipped with 12 U.2 NVMe SSD bays and support for SATA SSDs, allowing flexible storage configurations optimized for performance, capacity, or cost. Ideal for AI workloads, virtualization, and real-time data processing.
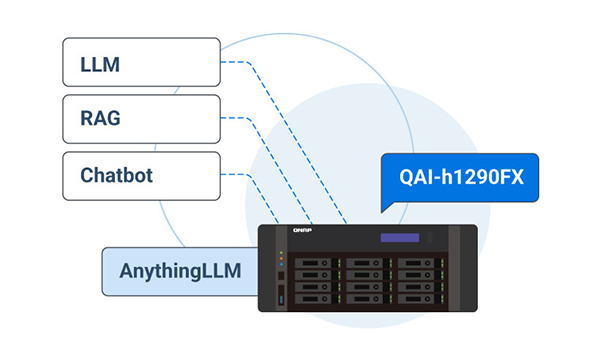
On-Premise LLM & RAG Search
Enables local deployment of private LLMs and RAG-based search, providing secure semantic document retrieval without sending sensitive data to the cloud.
ZFS-based QuTS hero OS
Powered by QuTS hero with ZFS, offering inline compression, self-healing, snapshots, and SnapSync for enterprise-grade data integrity.
GPU Acceleration & AI App Templates
Leverage GPU acceleration via Container Station. One-click deploy Ollama, AnythingLLM, Stable Diffusion, etc. Simplifying AI application rollout.
25GbE Connectivity & Expansion Ready
Built-in dual 25GbE and 2.5GbE ports, and upgradable for 100GbE. Scale up with QNAP JBODs to meet growing AI data storage demands.
Features:
QAI Ideal applications
Internal Chatbot & Knowledge Base
Deploy private ChatGPT-like bots using AnythingLLM or OpenWebUI. Securely connect to internal documents for employee Q&A, policy search, and training support—no internet required.
Private RAG Search Engine
Run Retrieval-Augmented Generation (RAG) locally with full control over data. Enable natural-language document search across contracts, reports, and archives—ideal for legal, finance, and enterprise teams.
AI Inference & Content Generation
Use Stable Diffusion or ComfyUI for image generation, or deploy custom models for video tagging, document summarization, and medical analysis. Benefit from GPU acceleration and all-flash storage.
Enterprise-Grade Edge AI and High-Performance Computing
QAI-h1290FX is more than a storage system — it is a compute-ready, enterprise-grade edge computing platform. Built on a high-performance computing architecture, it supports configurable NVIDIA® RTX™ Pro Blackwell GPUs, making it well-suited for large language model (LLM) inference, image generation, RAG search, and a wide range of compute-intensive and virtualized workloads.
Whether for AI inference, research and development, data analytics, or enterprise applications requiring high core counts and sustained performance, a single desktop-class enterprise platform can deliver outstanding compute efficiency and data security entirely on-premises.
Maximum AI Compute Performance (Optional GPU Configuration)
3511 AI TOPS (FP4) 333 TFLOPS (RT Core)
GPU-Ready Architecture — Supporting NVIDIA® RTX™ Pro Blackwell
QAI-h1290FX features a GPU-ready architecture designed to support NVIDIA® RTX™ Pro Blackwell GPUs. Built on the Blackwell architecture, it supports acceleration technologies such as CUDA, TensorRT, and the Transformer Engine, making it well-suited for modern AI and GPU-accelerated computing workloads.
From large language model (LLM) inference and computer vision to generative AI and other GPU-accelerated professional applications, workloads can be deployed and executed entirely on-premises—delivering strong performance while maintaining data privacy and full system control. The platform can also operate as a CPU-centric high-performance computing system, supporting virtualization and a wide range of enterprise computing scenarios.
Flagship
NVIDIA® RTX™ Pro 6000 Blackwell Max-Q Workstation
96 GB GDDR7 ECC memory
24,064 CUDA cores, 752 Tensor cores, 188 RT cores
125 TFLOPS (FP32), up to 4000 AI TOPS
1,792 GB/s memory bandwidth
300W power consumption
PCIe 5.0 x16 interface
Designed for large-scale LLMs (up to 70B+ parameters), multi-model parallel workloads, and high-throughput AI pipelines
Performance
NVIDIA® RTX™ Pro 4500 Blackwell
32 GB GDDR7 ECC memory
10,496 CUDA cores, 328 Tensor cores, 82 RT cores
54.94 TFLOPS (FP32)
896 GB/s memory bandwidth
200W power consumption
PCIe 5.0 x16 interface
Ideal for mid-sized LLMs (up to ~30B parameters), retrieval-augmented generation (RAG) pipelines, and high-performance graphics applications
NVIDIA® RTX™ Pro Blackwell Series — Redefining AI and High-Performance Computing Workflows
The NVIDIA® RTX™ Pro Blackwell series GPUs are purpose-built for high-intensity AI, compute, and creative workloads, combining the next-generation Blackwell architecture with ultra-fast GDDR7 ECC memory. This delivers a level of compute performance and VRAM capacity on a single professional GPU that previously required multiple consumer-grade graphics cards.
With support for up to 96GB of VRAM and enhanced AI acceleration capabilities, the RTX™ Pro Blackwell series is ideal for advanced LLMs, generative models, data analytics, and complex 3D visualization and professional compute workflows.
5th Gen Tensor Cores
Up to 3× faster AI processing with FP4 precision and DLSS 4 acceleration.
4th Gen RT Cores
2× faster ray tracing for photorealistic rendering and real-time simulations.
4th Gen RT Cores
2× faster ray tracing for photorealistic rendering and real-time simulations.
4th Gen RT Cores
2× faster ray tracing for photorealistic rendering and real-time simulations.
Powered by Server-Class AMD EPYC™ Processors for High-Performance Compute
QAI-h1290FX is built on a server-class AMD EPYC processor platform, delivering high core counts and massive multithreaded performance.
Designed for long-term, stable operation under highly parallel workloads, it is well suited for virtualization, multithreaded computing, data processing, and edge computing scenarios—while also supporting AI inference and a wide range of compute-intensive applications.
CPU
Server-class AMD EPYC™ processors High core-count and multithreaded architecture
Memory
128 GB RDIMM DDR4 ECC memory (Expandable up to 1 TB)
QuTS hero operating system
Designed for enterprises, the QuTS hero operating system adopts the highly reliable ZFS file system to provide utmost data integrity and stability for mission-critical storage. QuTS hero further optimizes SSD performance and endurance to meet businesses’ stringent demands for performance and reliability.
Automatic repair of corrupted data
ZFS supports self-healing for silent data corruption, automatically detecting damaged data to ensure data integrity.
Data immutability
Defend against ransomware by creating a WORM (Write Once, Read Many) folder to prevent data from being overwritten, modified, or deleted, while also enabling immutable backups.
Power failure protection
ZIL (ZFS Intent Log) protects against potential data corruption caused by power failure by safeguarding unwritten data.
Data reduction
Inline data deduplication reduces storage consumption for maintaining optimal disk capacity.
Prevent simultaneous SSD failure
The patented QSAL algorithm automatically and regularly detects RAID-level SSD lifespan to prevent simultaneous SSD failure, avoiding RAID crashes and data loss.
Remote access to on-prem AI – anytime, anywhere
Create a seamless hybrid work environment with multiple remote access options offered by QNAP. Whether you're managing AI applications or accessing files, the QAI-h1290FX ensures you're always connected—without compromising security.
Direct or relay access options
myQNAPcloud DDNS: Access your QuTS hero interface from anywhere via a custom domain, without remembering IP addresses.
myQNAPcloud Link: Establishes a secure relay connection through QNAP servers—no need to open router ports or modify firewall settings.
VPN Server Support: Set up a private VPN using QVPN Service, enabling secure encrypted tunnels for full network access.
Whether you're fine-tuning your LLM container setup, reviewing inference logs, or collaborating across locations, the QAI-h1290FX offers reliable access to your on-prem AI environment from any device, anytime.
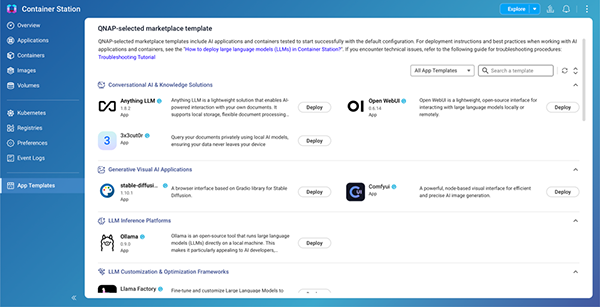
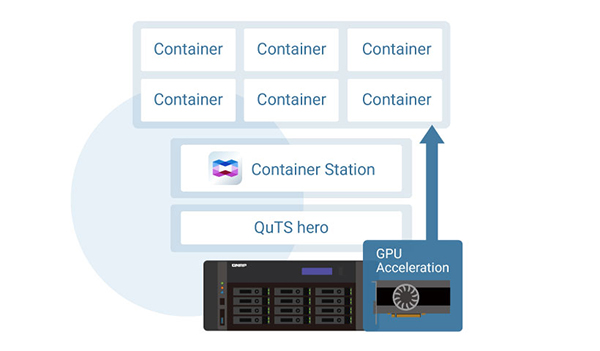
A More Powerful Container Station: A New Experience in AI Application Deployment
To promote practical AI adoption, the QAI series integrates Container Station with a wide selection of AI application templates. These templates support one-click deployment of popular AI tools and frameworks, with regular updatesfrom QNAP to ensure access to the latest technologies.
Whether you're new to AI or looking to move workloads on-premises, QAI makes it easy to explore AI, reduce costs, enhance data security, and even develop custom AI tools to boost business innovation.
Containerized AI deployment made simple
Enhance your AI infrastructure with seamless container integration.
AI-centric container environment
The QAI-h1290FX comes with Container Station, enabling the deployment of Docker and LXD containers. As most AI tools today are delivered as containerized applications, QAI-h1290FX provides a direct and efficient way to deploy models such as LLM, RAG Search, image generation (e.g. Stable Diffusion), or knowledge base engines like AnythingLLM—all without complex setup.
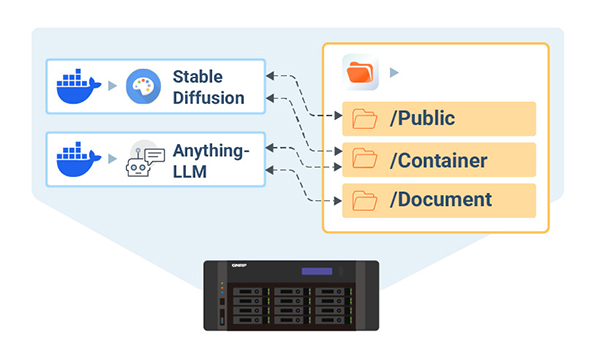
Persistent data storage for AI models
With Docker Volume support, the QAI-h1290FX allows containers to mount shared folders from the NAS, ensuring persistent storage even after container rebuilds. This is especially beneficial for AI workloads involving large model files, training data, or logs. No more worrying about losing key data during updates or version switching.
Make GPU acceleration simple and accessible for all AI workloads
The QAI-h1290FX removes the complexity of configuring GPU resources in Docker environments. With Container Station’s intuitive interface, when creating a new container, simply select the desired NVIDIA® GPU from the dropdown menu, and the container will instantly gain access to GPU compute capabilities. Whether you're deploying LLMs, running image generation, or executing deep learning inference, the QAI-h1290FX ensures the process is seamless and efficient.
Redefining creativity with AI-powered visual design
ComfyUI empowers artists, designers, and content creators with a powerful, modular interface for AI-driven image and video creation. Through its intuitive node-based design and support for advanced models like Stable Diffusion, users can effortlessly generate, transform, and animate visual content. Combined with GPU acceleration and flexible workflows, ComfyUI lowers the barrier to complex visual design—unlocking unprecedented creative freedom.
Text-to-Image Generation
Turn simple text prompts into high-quality visuals using Stable Diffusion and custom models. Create concept art, product designs, or stylized scenes—perfect for creative and marketing teams looking to accelerate ideation.
Style Customization with Multiple Models
Choose from a wide range of supported checkpoints and LoRA models to achieve distinct visual styles. Whether it's photorealism, anime, or painterly art, every output can match your creative direction.
Image-to-Video Animation
Bring still images to life by creating smooth animations and cinematic sequences. ComfyUI supports frame interpolation and style transfer to turn static visuals into engaging motion graphics.
Visual Workflow Editing for Custom Pipelines
Build and refine complex visual pipelines using ComfyUI’s intuitive node editor. Connect models, effects, and processing steps in a visual interface that empowers experimentation and creative control & no coding required.
Real-world AI performance – measured on QAI-h1290FX
AI deployment performance is validated through real-world benchmark data. Under a high-end GPU test configuration, QAI-h1290FX was fully evaluated with the NVIDIA® RTX™ PRO 6000 Blackwell Max-Q Workstation GPU, verifying its performance in on-premises AI inference and enterprise deployment scenarios.
Ollama LLM Inference Benchmark (Rapid Deployment)
Leveraging the GPU acceleration capabilities of the Blackwell architecture, QAI-h1290FX can run a wide range of large language models locally via Ollama. Ollama enables rapid deployment and simplified management, making it well suited for proof-of-concept (PoC) projects, single-user environments, and small to mid-scale use cases such as RAG-based search, AI assistants, and offline inference.
To address multi-user and high-concurrency AI service requirements, QAI-h1290FX also supports deployment with the vLLM inference engine. Compared to single-request–oriented inference approaches, vLLM significantly improves GPU utilization and overall throughput through Paged Attention and efficient scheduling mechanisms. This makes it particularly suitable for enterprise AI services, multi-user RAG systems, and API-based AI applications.
Under the same GPU configuration, vLLM demonstrates more consistent latency characteristics and higher tokens-per-second throughput in concurrent request scenarios, making it ideal for production environments and long-running enterprise AI deployments.
Tested Large Language Model : deepseek-ai/DeepSeek-R1-Distill-Qwen-7B (Hugging Face)
Thread
Total Token/sec
avg Token/Thread/Sec
1
79 Token/sec
79 Token/sec
2
166 Token/sec
83 Token/sec
5
410 Token/sec
82 Token/sec
10
688 Token/sec
68.8 Token/sec>
20
810 Token/sec
40.5 Token/sec
50
850 Token/sec
17 Token/sec
Tested Large Language Model : openai/gpt-oss-20b (Hugging Face)
Thread
Total Token/sec
avg Token/Thread/Sec
1
218 Token/sec
218 Token/sec
2
340 Token/sec
170 Token/sec
5
1045 Token/sec
209 Token/sec
10
880 Token/sec
88 Token/sec>
20
600 Token/sec
30 Token/sec
Benchmark results are based on the average performance from multiple prompts across various domains, such as mathematics, physics, computer science, and philosophy.
Unlock AI potential with practical use cases
From document automation to creative workflows and system-wide automation, the QAI-h1290FX empowers every department to apply AI in meaningful, measurable ways—securely hosted on your own infrastructure.
No cloud lock-in, no complex setup—just real results driven by local LLMs, secure containers, and integrated QNAP features.
Smart HR Assistant – Internal Policy Chatbot
Build an internal Q&A assistant using AnythingLLM + Ollama. Upload HR documents such as employee handbooks, leave policies, and benefits to the QAI-h1290FX. Employees can ask natural questions like:
“How do I apply for family care leave?”
The system performs local RAG search and replies instantly, reducing HR workload and improving response time.
Creative Team AI Studio – Image Generation Hub
Design teams use Stable Diffusion and ComfyUI deployed on the QAI-h1290FX to generate promotional images, mockups, or stylized artwork via prompt input.
Thanks to GPU acceleration and persistent NAS storage, designers get fast and reproducible results—no more starting from scratch.
AI Co-Pilot for Developers – Docs, Code & Summaries
Engineering teams run LLMs like Qwen or Llama in Ollama on the QAI-h1290FX to assist with spec writing, code review, and technical translations.
Upload API docs or whitepapers, then chat with the model for clarifications, summaries, or even markdown formatting—completely offline and secure.
n8n + NAS Automation – Trigger AI from Anywhere
With n8n installed on the QAI-h1290FX, you can automate tasks that integrate AI with business operations. For example:
When receiving a support email, trigger LLM to summarize and provide suggested responses, saving them in drafts.
Connect to QNAP MCP to regularly check device status, and provide suggestions to users after AI analysis.
Analyze NAS backed-up emails and conversations with LLM to check if there is any inappropriate content
AI Docker applications on QAI-h1290FX
Run powerful AI solutions via Container Station & GPU integration.
AnythingLLM
Enables teams to deploy customizable, private Large Language Models in a secure environment. Integrate various data sources and interact with your LLM for tailored Q&A, document parsing, and more—ideal for businesses prioritizing privacy and control.
OpenWebUI
A versatile and user-friendly web interface for interacting with local or remote LLMs. OpenWebUI supports chat, prompt engineering, and conversation management in a sleek UI, simplifying AI adoption for users and developers alike.
Ollama
Ollama makes running and experimenting with open-source language models effortless. With GPU support, developers can efficiently test, fine-tune, and serve powerful LLMs on-premises, keeping data secure and workflows agile.
ComfyUI
An advanced, modular UI for generative AI workflows. ComfyUI allows users to create, visualize, and customize complex AI pipelines—including image synthesis and text-to-image tasks—using an intuitive drag-and-drop interface powered by GPU acceleration.
n8n
n8n is a workflow automation tool that connects to hundreds of services, including AI models. Integrate business operations, trigger AI tasks, and automate repetitive processes—all within a secure, containerized environment, with support for powerful extensions and custom logic.
Whisper
Whisper delivers versatile, multilingual speech processing in a single, open-source model. It accurately transcribes, translates, and identifies languages from diverse audio sources, enabling seamless voice-to-text workflows across industries. With support for on-premises deployment, teams can maintain data security while integrating advanced speech capabilities into their applications.
Transform your NAS into an AI-powered knowledge hub
Empower enterprise users to search, understand, and retrieve information faster than ever—powered by Qsirch and next-generation RAG Search. The QAI-h1290FX brings intelligence to your documents while keeping everything secure and on-premises.
Qsirch – Smart Full-Text Search
Qsirch offers blazing-fast full-text search across all your NAS files—PDFs, Office docs, emails, and more. With advanced filters, indexing, and preview functions, users can locate relevant documents instantly across terabytes of data.
RAG Search – AI-Powered Contextual Answers
RAG (Retrieval-Augmented Generation) Search takes things further by combining Qsirch with a local Large Language Model (LLM). When users ask a question, the system first retrieves relevant files via Qsirch, then generates an accurate, natural language answer using the on-device AI.
On QAI-h1290FX, RAG Search is fully on-premise:
✓ No cloud APIs
✓ No data leaks
✓ Complete privacy and compliance
5-year warranty as standard
The QAI-h1290FX is backed by a 5-year warranty at no extra cost – providing your business organization with greater peace of mind.
Hardware Specifications:
QAI-h1290FX-7302P-128G
CPU
AMD EPYC™ 7302P 16-core/32-thread processor, up to 3.3 GHz
CPU Architecture
64-bit x86
Encryption Engine
(AES-NI)
System Memory
128 GB RDIMM DDR4 ECC
Maximum Memory
1 TB (8 x 128 GB)
Memory Slot
8 x RDIMM DDR4
Flash Memory
8GB (Dual boot OS protection)
Drive Bay
12 x 2.5-inch U.2 PCIe NVMe / SATA 6Gbps
The system is shipped without SSD
Drive Compatibility
2.5-inch bays: 2.5-inch SATA solid state drives 2.5-inch U.2 NVMe PCIe Gen4 x4 solid state drives
Hot-swappable
SSD Cache Acceleration Support
GPU pass-through
SR-IOV
2.5 Gigabit Ethernet Port (2.5G/1G/100M)
2 (2.5G/1G/100M/10M)
25 Gigabit Ethernet Port
2 x 25GbE SFP28 SmartNIC port
Wake on LAN (WOL)
Only the 2.5GbE port
Jumbo Frame
PCIe Slot
4 Slot 1: PCIe Gen 4 x 16 Slot 2: PCIe Gen 4 x 16 Slot 3: PCIe Gen 4 x 8 Slot 4: PCIe Gen 4 x 16 Card dimensions for PCIe slot 1 & Slot 2:185 x 111.15 x 18.76 mm / 7.28 x 4.38 x 0.74 inches. Card dimensions for PCIe slot 3 & Slot 4:280 x 111.15 x 18.76 mm / 11.02 x 4.38 x 0.74 inches. Wider cards can be installed if the next PCIe slot will not be used.
USB 3.2 Gen 1 port
3
Form Factor
Tower
LED Indicators
Power/Status, LAN, USB, SSD1-12
LCD Display/ Button
Buttons
Power, Reset, USB Auto Copy
Dimensions (HxWxD)
150 × 368 × 362 mm Dimensions do not include foot pad (foot pad may be up to 10mm / 0.39 inches high depending on model)
Weight (Net)
10.4 kg
Weight (Gross)
11.3 kg
Operating temperature
0 - 40°C (32°F - 104°F)
Storage Temperature
-20 - 70°C (-4°F - 158°F)
Relative Humidity
5-95% RH non-condensing, wet bulb: 27°C (80.6°F)
Power Supply Unit
750W, 100-240V
Fan
2 x 92mm, 12VDC
System Warning
Buzzer
Kensington Security Slot
Max. Number of Concurrent Connections (CIFS) - with Max. Memory
10,000
Note: Use only QNAP memory modules to maintain system performance and stability. For NAS devices with more than one memory slot, use QNAP modules with identical specifications and refer to the hardware user manual to install compatible QNAP memory modules. Warning: Using unsupported modules may degrade performance, cause errors, or prevent the operating system from starting. QNAP reserves the right to replace partial parts or accessories if the original is no longer available from its manufacturer/supplier. Any replacement would be fully tested and verified to meet strict compatibility and stability guidelines and will deliver identical performance to the original. The terms HDMI, HDMI High-Definition Multimedia Interface, HDMI trade dress and the HDMI Logos are trademarks or registered trademarks of HDMI Licensing Administrator, Inc. Product images are for illustrative purposes only and may differ from the actual product. Due to differences in monitors, colors of products may also appear different to those shown on the site. Designs and specifications are subject to change without notice.
Pricing Notes:
Pricing and product availability subject to change without notice.
QNAP Products
QNAP 12-Bay U.2 NVMe PCIe Gen4 x4 all-flash desktop NAS, AMD EPYC 16-core 7302P, 12 x 2.5″ U.2 NVMe / SATA SSD bays, 128GB RDIMM ECC DDR4 RAM, 2 x 2.5GbE RJ45, 2 x 25GbE SFP28, PCIe Gen4 expansion slots, 750W single power supply with dual PCIe 8pin, up to 300W GPU AMD EPYC™ 7302P, 16C/32T up to 3.3 GHz
#QAI-h1290FX-7302P-128G-US Get a Quote!
Storage Expansion Card
Dual M.2 22110/2280 PCIe SSD expansion card (PCIe Gen2 x4) Low-profile bracket pre-loaded, Low-profile flat and Full-height are bundled *shorter version to support TVS-x82/TS-x77 PCIe slot 2 & slot 3
#QM2-2P-244A Get a Quote!
Dual M.2 PCIe SSD expansion card; supports up to two M.2 2280/22110 formfactor M.2 PCIe (Gen3 x4) SSDs; PCIe Gen3 x4 host interface; Low-profile bracket pre-loaded, Low-profile flat and Full-height are bundled TVS-hx74, TVS-1282T3, TS-hx87XU-RP, TS-1655
#QM2-2P-344A Get a Quote!
Dual M.2 PCIe SSD expansion card; supports up to two M.2 2280/22110 formfactor M.2 PCIe (Gen3 x4) SSDs; PCIe Gen3 x8 host interface. Low-profile bracket pre-loaded, Low-profile flat and Full-height are bundled
#QM2-2P-384A Get a Quote!
QM2 series, 2 x PCIe 2280 M.2 SSD slots, PCIe Gen3 x 8 , 1 x AQC113C 10GbE NBASE-T port
#QM2-2P10G1TB Get a Quote!
QNAP QM2 series, 2 x PCIe 2280 M.2 SSD slots, PCIe Gen3 x 4 , 2 x Intel I225LM 2.5GbE NBASE-T port
#QM2-2P2G2T Get a Quote!
Dual M.2 22110/2280 SATA SSD expansion card (PCIe Gen2 x2) Low-profile bracket pre-loaded, Low-profile flat and Full-height are bundled *shorter version to support TVS-x82/TS-x77 PCIe slot 2 & slot 3
#QM2-2S-220A Get a Quote!
Quad M.2 PCIe SSD expansion card; supports up to four M.2 2280 formfactor M.2 PCIe (Gen3 x4) SSDs; PCIe Gen3 x8 host interface; Low-profile bracket pre-loaded, Low-profile flat and Full-height are bundled
Single-port (10Gbase-T) 10GbE network expansion card, PCIe Gen3 x4, Low-profile bracket pre-loaded, Low-profile flat and Full-height bracksts are bundled All NAS models with a PCIe slot.
Dual-port BASET 10GbE network expansion card; low-profile form factor; PCIe Gen3 x4; Aquantia AQC107 All NAS models with a PCIe slot.
#QXG-10G2T Get a Quote!
Dual-port (10GBASE-T) 10GbE network expansion card, Intel X710, PCIe Gen3 x4 PCIe supported NAS and Windows 8/10/Windows Server/Linux/uBuntu/ RHEL PCs. Visit https://www.qnap.com/go/compatibility for the compatibible NAS.
#QXG-10G2T-X710 Get a Quote!
Dual-port SFP28 25GbE network expansion card; low-profile form factor; PCIe Gen4 x8 PCIe supported NAS
#QXG-25G2SF-CX6 Get a Quote!
Dual-port SFP28 25GbE network expansion card; low-profile form factor; PCIe Gen4 x8 PCIe supported NAS
#QXG-25G2SF-E810 Get a Quote!
Single port 2.5GbE 4-speed Network card PCIe supported NAS and Windows 10/ Windows Server 2016 & 2019 /Linux PCs. Visit https://www.qnap.com/go/compatibility for the compatibible NAS.
#QXG-2G1T-I225 Get a Quote!
Dual port 2.5GbE 4-speed Network card PC/Server or NAS with a PCIe slot
#QXG-2G2T-I225 Get a Quote!
Quad port 2.5GbE 4-speed Network card PC/Server or NAS with a PCIe slot
#QXG-2G4T-I225 Get a Quote!
QNAP 5GbE multi-Gig expansion card;Aquantia AQC111C;Gen2 x 1;low profile PCIe supported NAS
#QXG-5G1T-111C Get a Quote!
Interface Expansion
16G Fibre Channel Host Bus Adapter, 2 x transceivers are included
#QXP-16G2FC Get a Quote!
32G Fibre Channel Host Bus Adapter, 2 x transceivers are included
#QXP-32G2FC Get a Quote!
2 ports (SFF-8644) Expansion card; PCIe Gen3 x4 for QNAP PCIe JBOD series. Recommend installed in TS-h3087XU-RP, TS-h2287XU-RP, TS-h1887XU-RP, TS-h2490FU, TS-855eU(RP), also support TS-h987XU-RP, TDS-h2489FU, TS-h1090FU speed up to 32Gbps.
#QXP-3X4PES Get a Quote!
2 ports (SFF-8644 1x2) Expansion card; PCIe Gen3 x8 for QNAP PCIe JBOD series. Recommend installed in TS-h987XU-RP, TDS-h2489FU, TS-h1090FU speed up to 64Gbps, also support TS-h3087XU-RP, TS-h2287XU-RP, TS-h1887XU-RP, TS-h2490FU, TS-855eU(RP) speed up to 32Gbps